4. 데이터 분석 및 모델링 _ (1) 데이터 분할
[ Data Analysis Process ]
1. 분석 주제 정의
2. 데이터 수집
3. 데이터 전처리
4. 데이터 분석 및 모델링
1) 데이터 분할
2) 분석 모델 설정
3) 분석 모형 정의
4) 모델 검증/테스트
5. 결과 해석 및 시각화
데이터 분할
: 모델의 성능 향상과 과적합 문제의 방지를 위해 적절한 데이터 분할이 필요
1. 과적합
- 과적합은 모델의 복잡도와 학습 데이터의 양에 영향을 받음
1) 과대적합(Overfitting)
: 모델이 훈련 데이터에 지나치게 최적화되어 일반화된 성능을 나타내지 못하는 문제 (high bias)
→ 모델이 훈련 데이터에 대해서는 높은 정확도를 보이지만, 새로운 데이터에 대해서는 성능이 낮아짐
💡해결 방법
- 데이터 수 늘리기
- 파라미터 수가 적은 모델을 선택 → 모델의 복잡도 ↓
- 훈련 데이터에 포함된 feature(특성) 수 줄이기
- 모델에 가중치 규제 적용
- 훈련 데이터의 편향을 제거
2) 과소적합(Underfitting)
: 모델이 지나치게 단순해 데이터에 내재된 패턴을 효과적으로 학습하지 못하는 문제 (high variance)
💡해결방법
- 파라미터 수가 더 많은 최적화된 모델 선택 → 모델의 복잡도 ↑
- 모델에 대한 제약을 최소화

2. 데이터 분할(Data Splitting)
- Training(훈련·학습) 데이터 : 모델의 학습을 위한 데이터
- Validation(검증) 데이터 : 학습된 모델의 성능을 평가하 fine tuning을 수행하기 위한 데이터
- Test(평가) 데이터 : 최종 모델의 성능을 독립적으로 검증하기 위한 데이터
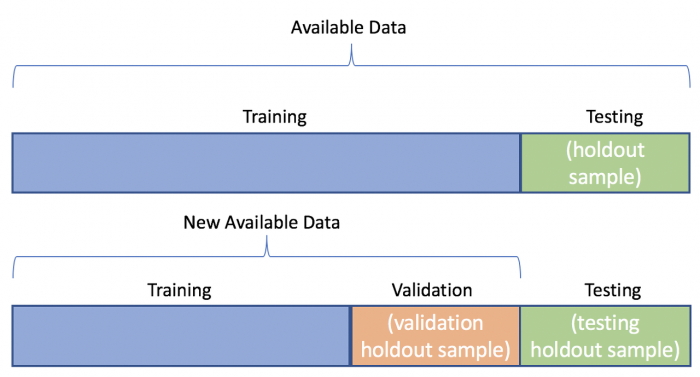
1) 데이터 분할 방법
(1) Hold-out(예비법) : 보편적 방법, 전체 데이터를 목적에 따라 겹치지 않게 랜덤 추출로 데이터 분할
- Training/Validation Set : 60~80%
- Test Set : 20~40%
(2) Cross Validation(교차타당성 검증) : 과적합을 방지하고 더 신뢰성 있는 모델 평가를 진행하기 위함, 훈련용, 테스트용 역할을 데이터가 교차로 수행
- 모든 데이터를 모델의 훈련, 평가에 활용할 수 있음
- Iteration 횟수가 많기 때문에, 모델 훈련/평가 시간이 많이 소요됨
🗂️ 대표적 Cross Validation 기법 종류
① K-Fold Cross Validation : K개의 데이터 폴드 세트를 만들어 K번만큼 각 set에 훈련, 검증 평가를 반복적으로 수행
- 보통 회귀 모델에 사용
- 데이터가 독립적이고 동일한 분포를 가진 경우에 사용

② Stratified K-Fold Cross Validation : 불균형한 분포를 가진 레이블 데이터 집합을 위한 K-Fold 방법
* 레이블 분포가 유사하도록 train set, test set을 분배해 데이터 편향 문제를 방지
(3) Bootstrap : 훈련용 데이터를 복원추출(리샘플)하는 방법
* 머신러닝 모델 중 배깅(Bagging) 방식의 앙상블 모델에서 사용하는 데이터 분할 방식 - 오분류한 데이터에 가중치를 둠