패스트캠퍼스 환급챌린지 18일차 미션 (2월 18일) : 데이터 분석 Master Class 강의 후기
오늘은 3번째로 설문지를 제출하는 날!
18일차 빠밤

오늘은 SQL을 활용한 데이터의 생성과 조회 마지막 시간이었다.
JOIN과 서브쿼리에 이어 UNION, ROLL UP, 윈도우 함수를 배울 수 있었다.
UNION의 경우 개념이나 사용하는 방법은 쉬웠다.
하지만 MySQL에서 INTERSECT와 MINUS를 사용하지 못하는 것은 몰랐는데
MySQL에서 EXISTS 구문을 통해 사용하는 방법을 배울 수 있어 좋았다.
특히 이렇게 예제를 하나하나 알아가면서 명령어들을 다양하게 사용할 수 있는 방법을 배워갈 수 있었다.
ROLL UP의 경우 처음 배워본 개념이었지만 어렵지 않은 개념이었다.
특히 ROLL UP을 사용할 경우 합계와 소계를 바로 계산해줘
데이터 집계를 일일이 할 필요없이 사용할 수 있어 유용한 명령어인 것 같다.
그리고 GROUP BY를 할 때 컬럼의 순서 중요⭐
마지막으로 윈도우 함수는 SQL에 대해 이것저것 서칭해보다가 이름만 들었던 개념이었다.
나도 처음에 윈도우 함수라는 이름을 들었을 때 OS에 관련된 건가라는 생각이 들었었는데
강사님도 그런 생각이 들었다고 한다. 나만 그런게 아니었군ㅋㅋ
윈도우 함수는 처음에 뭐지,,? 이런 생각이 들었던 개념이었다.
그래서 이해를 위해 강의를 여러 번 반복해서 들었고 예제 테이블이 마땅치 않아
기존 나눠주었던 자료에서 예제를 수정하여 실습을 진행했는데
예제를 직접해보며 이해할 수 있었다.
특히 윈도우 함수는 간결한 SQL로 많은 데이터를 도출할 수 있어 개념을 잘 숙지해서 잘 활용하고 싶다🤗
Part 2. SQL _ 데이터 생성과 조회 2
05. 집합 연산자
: 데이터를 세로로 연산해줌
+ 가로 연산: JOIN
// 실습 데이터: 자료 Part 6의 world_tour.sql
1. UNION ALL
: 중복 데이터 제거 X인 합집합
select * from world_tour1
union all
select * from world_tour2;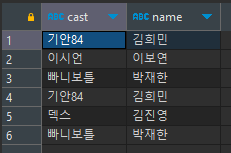
* 주의: select하는 컬럼의 개수가 같아야 함
- 개수가 동일하다면 컬럼의 순서는 상관없음
-- 동일한 결과 출력 --
select cast, name from world_tour1
union all
select name, cast from world_tour2;
- alias를 붙이고 싶다면 제일 위에 위치한 컬럼에만 붙이면 됨

2. UNION
: 중복된 데이터 제거(DISTINCT)하는 합집합
+ intersect, minus
: MySQL의 경우 intersect(교집합), minus(차집합)을 지원하지 않기 때문에 exists를 이용해야 함
/* intersect */
select * from world_tour a
where exists (select 1 from world_tour2 b where a.cast = b.cast);
/* minus */
select * from world_tour a
where not exists (select 1 from world_tour2 b where a.cast = b.cast);
06. WITH ROLLUP
: 데이터를 집계한 후 소계나 합계를 구할 때 사용
// 실습 데이터: 자료 Part 4의 animal.sql
1. 합계
select animal, count(*) from animal_info group by animal with rollup;
2. 합계, 소계
select animal, type, count(*) from animal_info group by animal, type with rollup;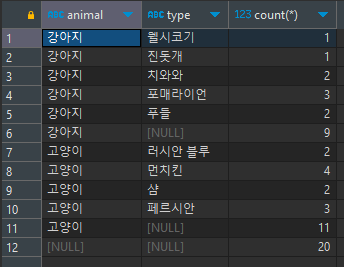
* 주의: ROLL UP을 사용할 때에는 GROUO BY절의 컬럼의 순서에 영향을 받으므로 이를 고려해서 작성해야 함
select animal, type, count(*) from animal_info group by type, animal with rollup;
3. CASE WHEN
select case when animal is null then 'total' else animal end as animal,
case when type is null then 'total' else type end as type,
count(*)
from animal_info
group by animal, type with rollup;* CASE WHEN 구문의 마지막 'END AS 컬럼' CASE WHEN 구문 사용으로 생긴 새로운 열의 이름을 지정하는 것

07. 윈도우 함수
: 테이블의 특정 부분을 대상으로 데이터를 계산해주는 함수
// 실습 테이블: 자료 Part 6의 idol.sql
1. 그룹별 멤버 수
- 윈도우 함수
select group_name,
count(*) over(partition by group_name) as member_cnt
from idol_member;
· count(*) 다음 over절
· partition by: 파티션이 될 컬럼

- GROUP BY
select group_name, count(*) from idol_member group by group_name;
2. 순위 매기기
// 실습 테이블: 자료 Part 4의 book_list.sql 을 수정하여 사용
genre 컬럼을 추가하고 price 컬럼의 데이터를 수정하였기 때문에 기존의 테이블을 삭제 후 진행함
/* 기존 테이블 삭제 */
drop table book_list;
/* 테이블 생성 */
CREATE TABLE book_list (
book_no varchar(13),
book_nm varchar(30),
writer varchar(20),
publisher varchar(30),
reg_date date,
price int,
genre varchar(10)
);
INSERT INTO book_list VALUES ('9791168473690','세이노의 가르침','세이노','데이원','20230302',7200, '자기계발');
INSERT INTO book_list VALUES ('9791158741952','상처받지 않는 관계의 비밀','최리나','미디어숲','20230730',17500, '자기계발');
INSERT INTO book_list VALUES ('9788901272580','역행자','자청','웅진지식하우스','20230529',19500, '자기계발');
INSERT INTO book_list VALUES ('9788932923413','꿀벌의 예언1','베르나르 베르베르','열린책들','20230621',16800, 'SF');
INSERT INTO book_list VALUES ('9791191891287','메리골드 마음 세탁소','윤정은','북로망스','20230306',15000, '판타지');
INSERT INTO book_list VALUES ('9791191669466','나는 죽을 때까지 지적이고 싶다','양원근','정민미디어','20230615',16800, '에세이');
INSERT INTO book_list VALUES ('9791158741952','심플 라이프','제시카 로즈 윌리엄스','밀리언서재','20230615',17500, '자기계발');
INSERT INTO book_list VALUES ('9791190299770','모든 삶은 흐른다','로랑스 드빌레르','피카(FIKA)','20230403',16800, '에세이');
INSERT INTO book_list VALUES ('9791192389073','유연함의 힘','수잔 애쉬포드','상상스퀘어','20230510',19800, '자기계발');
INSERT INTO book_list VALUES ('9791167740984','도둑맞은 집중력','요한 하리','어크로스','20230428',18800, '인문');
- 순위를 매기는 함수
① row_number: 모두 다른 순위, 동일 데이터의 경우 random으로 순위 지정
ex) 1, 2, 3, 4, 5, 6, ...
② rank: 동일 데이터는 같은 순위, 다음 데이터는 동일 데이터만큼 뛰어넘은 후 순위 지정
ex) 1, 2, 2, 2, 5, 5, 7, ...
③ dense rank: 동일 데이터는 같은 순위, 다음 데이터는 차례대로 순위 지정
ex) 1, 2, 2, 2, 3, 4, 4, 5, ...
- 윈도우 함수
select book_no, book_nm, price, genre,
row_number() over(partition by genre order by price desc) as row_no,
rank() over(partition by genre order by price desc) as rank_no,
dense_rank() over(partition by genre order by price desc) as dense_rank_no
from book_list
order by genre, row_no;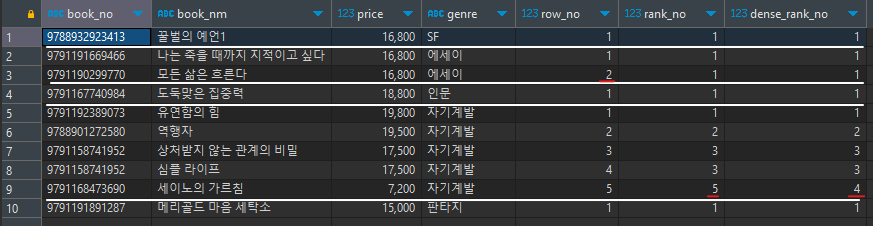
본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다.
패스트캠퍼스 [직장인 실무교육]
프로그래밍, 영상편집, UX/UI, 마케팅, 데이터 분석, 엑셀강의, The RED, 국비지원, 기업교육, 서비스 제공.
fastcampus.co.kr