패스트캠퍼스 환급챌린지 27일차 미션 (2월 27일) : 데이터 분석 Master Class 강의 후기
27일차!

오늘은 파이썬 기초의 자료형 파트의 마지막 시간!
처음에 목차를 보며 자료형 진짜 많다.. 라고 생각했었는데 벌써 모두 배웠다!
뿌-듯🤗
오늘은 딕셔너리, 집합, 불리언 자료형에 대해 배웠고 마지막 불리언은 정말정말 간단한 내용이었다!
그냥 불리언의 특징만 잘 기억해두면 된다=)
딕셔너리와 집합의 경우는 어렵진 않았다!
하지만 어제의 내용인 리스트, 튜플, 딕셔너리, 집합의 경우 각 특징을 잘 기억해두고
필요한대로 잘 조작해야 하는 것 같다.
이 부분이 조금 까다로운 정도?
특히 마지막 내용이었던 copy 함수에 대한 내용이 인상깊었다.
지금까지 파이썬을 이용하여 분석을 하면서 copy()를 사용하는 이유에 대해 모르고
왜 굳이 사용해야 하지라는 생각을 가져왔는데
오늘에서야 그 존재 이유에 대해 알게되었다ㅎㅎ
copy()를 사용하는 건 생각보다 되게 중요한 거였구나🤩
앞으로도 강의를 통해 파이썬에 대한 모르던 부분을 꼼꼼히 채워나가고 싶다👍
Part 3. PYTHON _ 파이썬 기초
02. 파이썬 기초
7. 자료형_딕셔너리
1) 딕셔너리
: 중괄호({})로 감싸진 키(Key):값(Value)의 쌍이 모여있는(맵핑이 되어있는) 사전 형태의 자료형
- 키는 중복 X, 리스트 자료형은 키가 될 수 없음(튜플은 변하지 않는 값이므로 가능)
- 위치 값을 가지지 않음 → 위치로 인덱싱 X
2) 딕셔너리 요소 추가, 삭제
- 추가: 딕셔너리 변수명[추가할 키] = 추가할 값
- 삭제: del 딕셔너리 변수명[추가할 키]
3) 딕셔너리 키로 값 찾기
딕셔너리 변수명[찾을 키]
4) 딕셔너리 함수
- keys() / values() / items() : 키 / 값 / 튜플 쌍(키:값)을 리턴
* 딕셔너리 함수들은 반복문과 자주 쓰임
* 결과를 리스트 형태로 반환하고 싶으면 list()로 감싸주기
- get(원하는 키 값) : 원하는 키 값에 대응되는 값 반환
== 딕셔너리 변수명[원하는 키 값]
- update : 딕셔너리에 새로운 딕셔너리 추가
dic1 = {'a':[1, 2], 'b':3, 'c':[4, 5, 6]}
dict2 = {'d':10, 'e':[11, 12]}
dic1.update(dic2) # {'a':[1, 2], 'b':3, 'c':[4, 5, 6], 'd':10, 'e':[11, 12]}
- zip : 튜플 / 리스트 두 개를 하나의 딕셔너리로 리턴
* 길이가 다른 리스트를 대응시키면 길이가 작은 것에 대응되어 딕셔너리 생성
# value가 튜플
keys = ('a', 'b')
values = (1, 2)
print(dict(zip(keys, values))) # {'a':1, 'b':2}
# values가 리스트
keys = ('a', 'b')
values = [1, 2]
print(dict(zip(keys, values))) # {'a':1, 'b':2}
# 키와 값의 리스트의 길이가 다를 때
keys = ['a', 'b', 'c']
values = [1, 2]
print(dict(zip(keys, values))) # {'a':1, 'b':2}
5) 데이터 셋과 대응
: 각 키들의 값의 길이가 같다면 dataframe(데이터 셋의 형식)과 대응 → 딕셔너리는 데이터 셋의 형식으로 쉽게 변환 가능
6) 연습문제
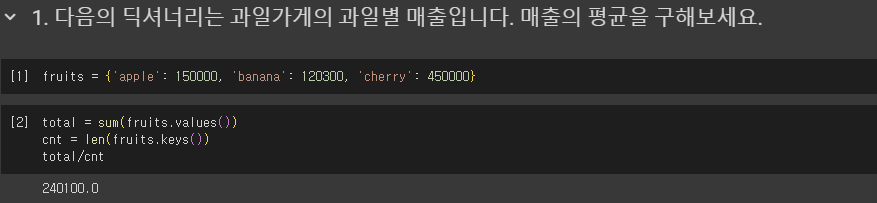

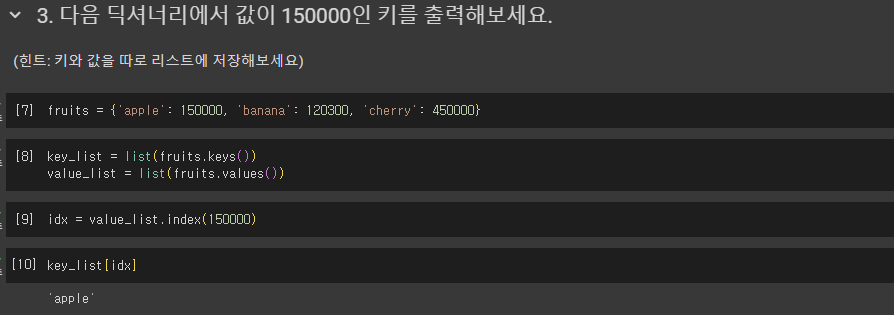
8. 자료형_집합, 불리언
1) 집합
: 중괄호({})로 감싸진 순서가 없고, 중복이 없는 자료형
s1 = set([1, 2, 'a'])
s1 # {1, 2, 'a'}
s2 = set('Hello')
s2 # {'e', 'l', 'o', 'H'}
s3 = set([1, 2, 2, 3, 5, 4])
s3 # {1, 2, 3, 4, 5}- 중복을 제거하고 싶을 때 사용
- 순서 X → 인덱싱 X (리스트나 튜플로 변환 후 인덱싱)
2) 집합 함수
- intersection or & : 교집합
- difference or - : 차집합
- union or | : 합집합
- add / remove : 요소를 추가 / 제거
3) 불리언
: 참, 거짓을 나타내는 자료형
- True, False로 나타냄
4) 연습문제
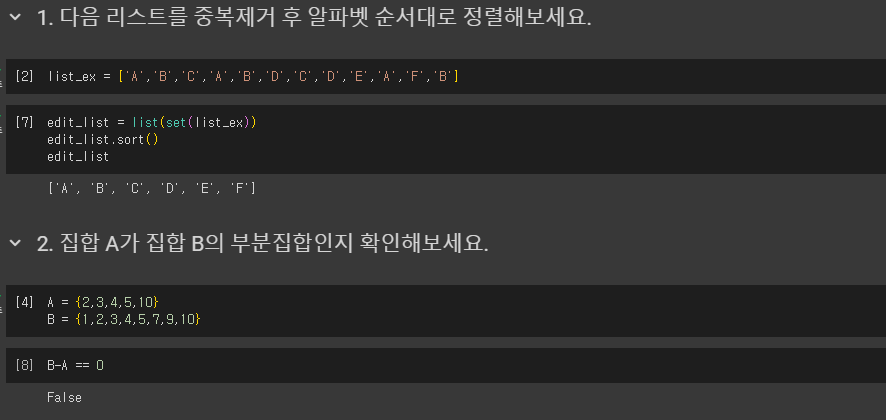
- 부분집합: A가 B의 부분집합이려면 A의 모든 원소가 B에 속해야 함 (issubset(): 부분집합 여부 확인 함수)
→ B와 A의 차집합 = 0
9. 변수 심화 _ copy()
변수란? 데이터의 저장공간
a = [1, 2, 3]
b = a위와 같다면 a와 b는 동일해짐
이때 a의 특정 인덱스 값을 바꾼다면?
a[2] = 4
print(a) # [1, 4, 3]
print(b) # [1. 4. 3]⇒ b의 결과값도 바뀜! 리스트 객체가 같기 때문!
: b = a를 선언하며 b에 a의 공간 값을 넣은 것과 같음
- id 함수(변수에 저장된 공간 id)를 통해 a, b의 id를 확인하면 동일한 것을 볼 수 있음
copy()
- b에 a의 값을 가져오면서 다른 주소를 가리키도록 하는 방법
: a의 값이 바뀌어도 b의 값은 이전의 값을 유지하도록(값만 저장이 되고 공간은 따로 할당)
a = [1, 2, 3]
b = a.copy()
print(a) # [1, 2, 3]
print(b) # [1. 2. 3]
print(a == b) # True: 값이 같기 때문
a[2] = 4
print(a) # [1, 4, 3]
print(b) # [1. 2. 3]
print(a == b) # False
본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다.
패스트캠퍼스 [직장인 실무교육]
프로그래밍, 영상편집, UX/UI, 마케팅, 데이터 분석, 엑셀강의, The RED, 국비지원, 기업교육, 서비스 제공.
fastcampus.co.kr